Warning: Deepseek
페이지 정보
작성자 Shayne Eisenber… 댓글 0건 조회 2회 작성일 25-02-01 06:39본문
The efficiency of an Deepseek mannequin depends closely on the hardware it's operating on. However, after some struggles with Synching up a few Nvidia GPU’s to it, we tried a unique method: working Ollama, which on Linux works very properly out of the field. But they find yourself continuing to solely lag a number of months or years behind what’s taking place within the leading Western labs. One in every of the important thing questions is to what extent that information will find yourself staying secret, each at a Western firm competition degree, as well as a China versus the remainder of the world’s labs degree. OpenAI, DeepMind, these are all labs which are working in direction of AGI, I would say. Or you might want a distinct product wrapper around the AI mannequin that the larger labs usually are not serious about building. So quite a lot of open-source work is things that you will get out shortly that get curiosity and get more folks looped into contributing to them versus a number of the labs do work that is maybe less applicable within the brief time period that hopefully turns right into a breakthrough later on. Small Agency of the Year" and the "Best Small Agency to Work For" in the U.S.
The educational fee begins with 2000 warmup steps, and then it's stepped to 31.6% of the maximum at 1.6 trillion tokens and 10% of the maximum at 1.8 trillion tokens. Step 1: Initially pre-skilled with a dataset consisting of 87% code, 10% code-associated language (Github Markdown and StackExchange), and 3% non-code-related Chinese language. deepseek ai-V3 assigns extra training tokens to study Chinese knowledge, leading to distinctive performance on the C-SimpleQA. Shawn Wang: I might say the leading open-source models are LLaMA and Mistral, and both of them are very popular bases for creating a leading open-source mannequin. What are the mental fashions or frameworks you use to suppose about the hole between what’s out there in open supply plus fantastic-tuning versus what the main labs produce? How open source raises the worldwide AI customary, however why there’s prone to all the time be a gap between closed and open-supply models. Therefore, it’s going to be laborious to get open supply to construct a better model than GPT-4, just because there’s so many things that go into it. Say all I want to do is take what’s open source and possibly tweak it somewhat bit for my particular firm, or use case, or language, or what have you ever.
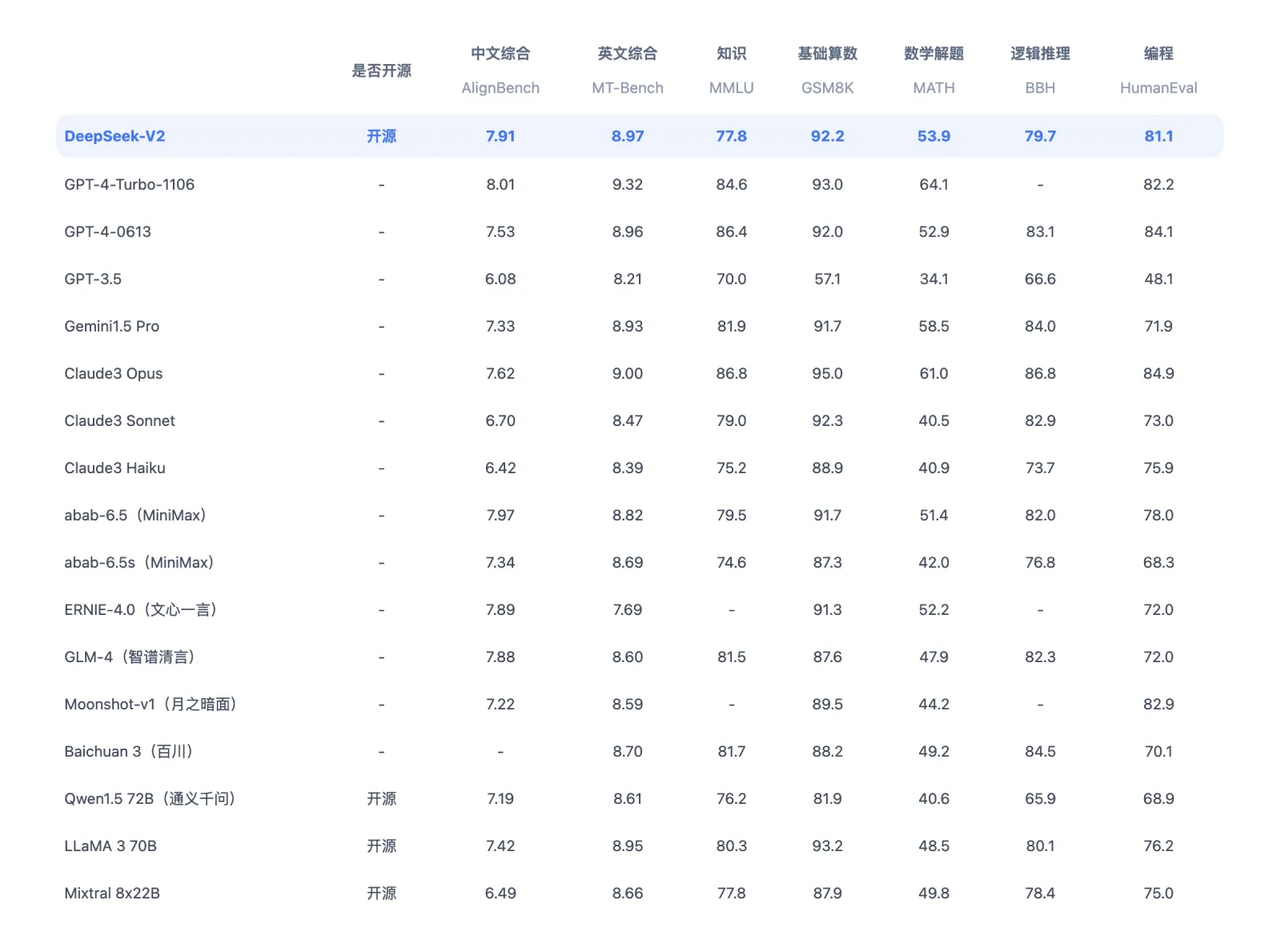 Typically, what you would want is some understanding of methods to superb-tune those open source-fashions. Alessio Fanelli: Yeah. And I think the opposite big factor about open source is retaining momentum. And then there are some superb-tuned knowledge sets, whether it’s synthetic data units or data sets that you’ve collected from some proprietary source someplace. Whereas, the GPU poors are usually pursuing more incremental modifications primarily based on techniques that are identified to work, that would improve the state-of-the-artwork open-source fashions a moderate amount. Python library with GPU accel, LangChain assist, and OpenAI-suitable AI server. Data is certainly at the core of it now that LLaMA and Mistral - it’s like a GPU donation to the general public. What’s concerned in riding on the coattails of LLaMA and co.? What’s new: DeepSeek announced free deepseek-R1, a mannequin family that processes prompts by breaking them down into steps. The intuition is: early reasoning steps require a rich space for exploring a number of potential paths, while later steps need precision to nail down the exact solution. Once they’ve performed this they do large-scale reinforcement studying training, which "focuses on enhancing the model’s reasoning capabilities, notably in reasoning-intensive tasks resembling coding, arithmetic, science, and logic reasoning, which involve nicely-outlined issues with clear solutions".
Typically, what you would want is some understanding of methods to superb-tune those open source-fashions. Alessio Fanelli: Yeah. And I think the opposite big factor about open source is retaining momentum. And then there are some superb-tuned knowledge sets, whether it’s synthetic data units or data sets that you’ve collected from some proprietary source someplace. Whereas, the GPU poors are usually pursuing more incremental modifications primarily based on techniques that are identified to work, that would improve the state-of-the-artwork open-source fashions a moderate amount. Python library with GPU accel, LangChain assist, and OpenAI-suitable AI server. Data is certainly at the core of it now that LLaMA and Mistral - it’s like a GPU donation to the general public. What’s concerned in riding on the coattails of LLaMA and co.? What’s new: DeepSeek announced free deepseek-R1, a mannequin family that processes prompts by breaking them down into steps. The intuition is: early reasoning steps require a rich space for exploring a number of potential paths, while later steps need precision to nail down the exact solution. Once they’ve performed this they do large-scale reinforcement studying training, which "focuses on enhancing the model’s reasoning capabilities, notably in reasoning-intensive tasks resembling coding, arithmetic, science, and logic reasoning, which involve nicely-outlined issues with clear solutions".
 This approach helps mitigate the chance of reward hacking in specific duties. The mannequin can ask the robots to carry out tasks and so they use onboard techniques and software program (e.g, local cameras and object detectors and movement policies) to help them do that. And software strikes so rapidly that in a manner it’s good since you don’t have all of the equipment to assemble. That’s undoubtedly the best way that you start. If the export controls find yourself taking part in out the way that the Biden administration hopes they do, then you might channel an entire country and multiple enormous billion-dollar startups and firms into going down these development paths. You possibly can go down the checklist in terms of Anthropic publishing plenty of interpretability analysis, however nothing on Claude. So you may have different incentives. The open-source world, so far, has more been about the "GPU poors." So should you don’t have a whole lot of GPUs, however you continue to want to get business value from AI, how can you do that? But, in order for you to construct a model better than GPT-4, you need a lot of money, you need a whole lot of compute, you need quite a bit of data, you want a lot of smart folks.
This approach helps mitigate the chance of reward hacking in specific duties. The mannequin can ask the robots to carry out tasks and so they use onboard techniques and software program (e.g, local cameras and object detectors and movement policies) to help them do that. And software strikes so rapidly that in a manner it’s good since you don’t have all of the equipment to assemble. That’s undoubtedly the best way that you start. If the export controls find yourself taking part in out the way that the Biden administration hopes they do, then you might channel an entire country and multiple enormous billion-dollar startups and firms into going down these development paths. You possibly can go down the checklist in terms of Anthropic publishing plenty of interpretability analysis, however nothing on Claude. So you may have different incentives. The open-source world, so far, has more been about the "GPU poors." So should you don’t have a whole lot of GPUs, however you continue to want to get business value from AI, how can you do that? But, in order for you to construct a model better than GPT-4, you need a lot of money, you need a whole lot of compute, you need quite a bit of data, you want a lot of smart folks.
- 이전글The Hallmarks Of A Sliding Garage Door 25.02.01
- 다음글인천 비아그라사진 파워맨 【 vCkk.top 】 25.02.01
댓글목록
등록된 댓글이 없습니다.